

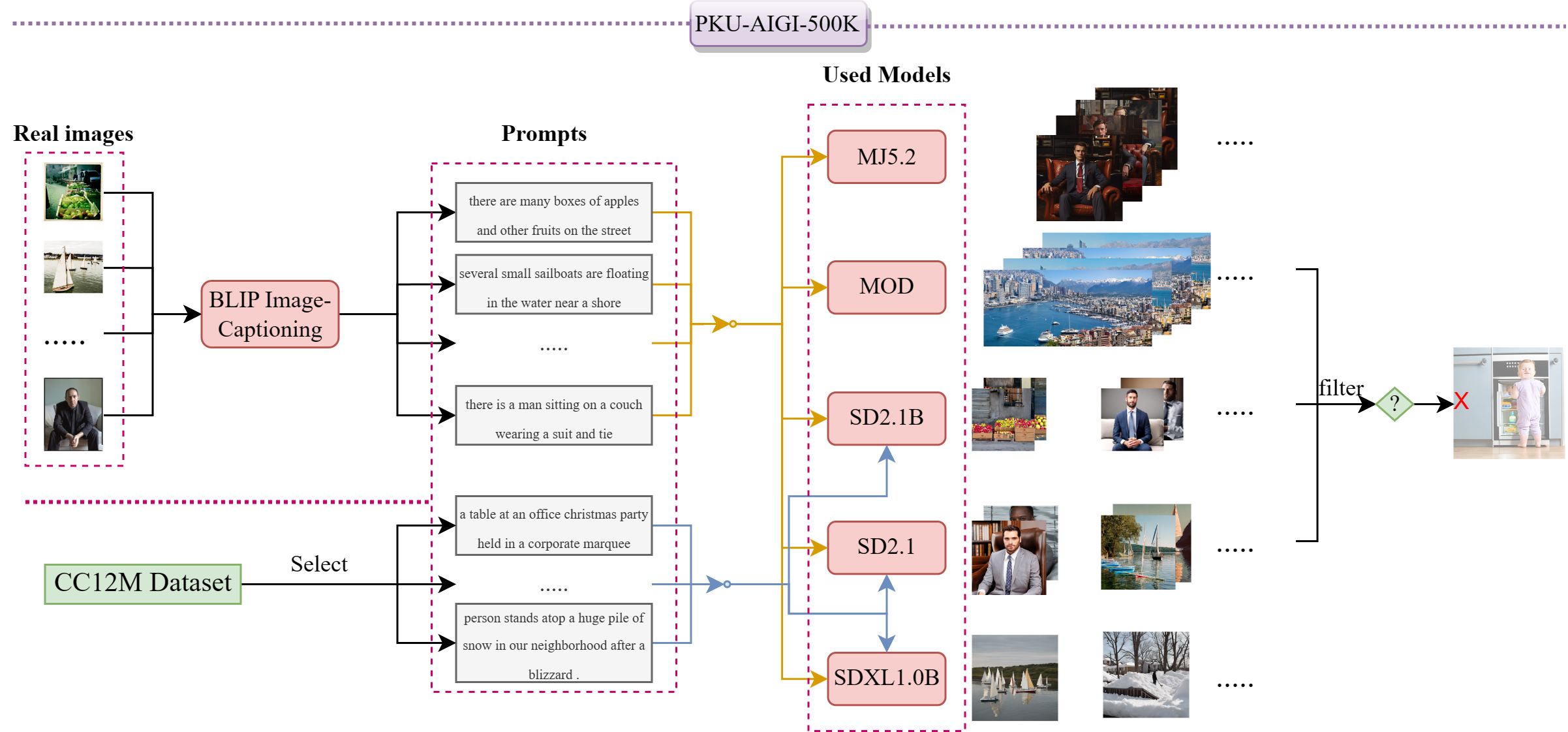
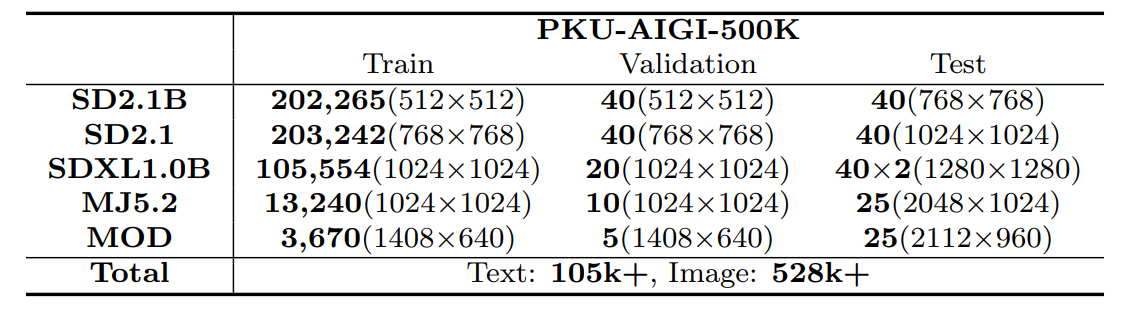
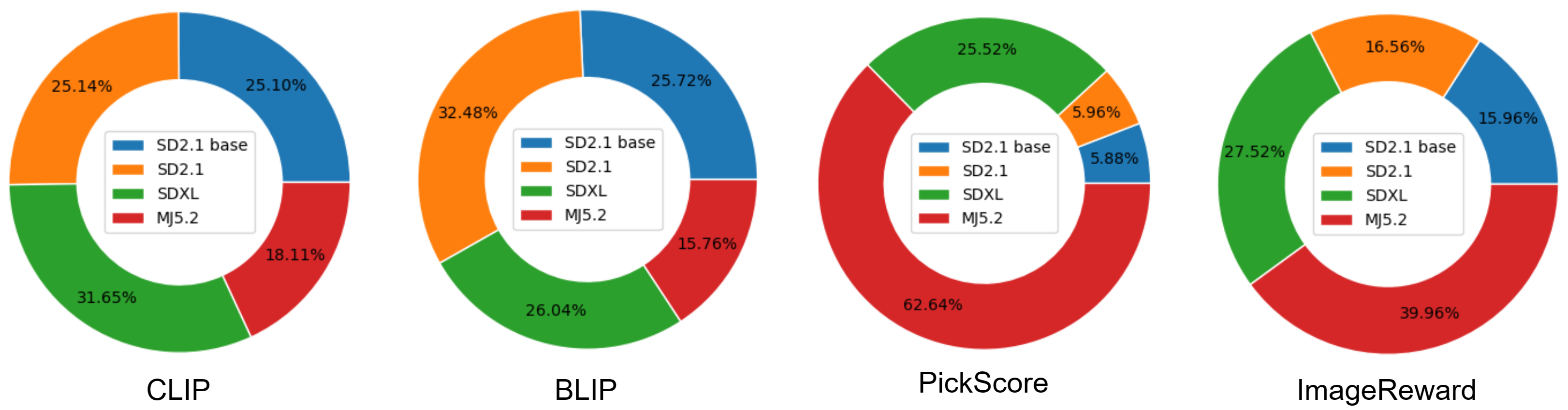
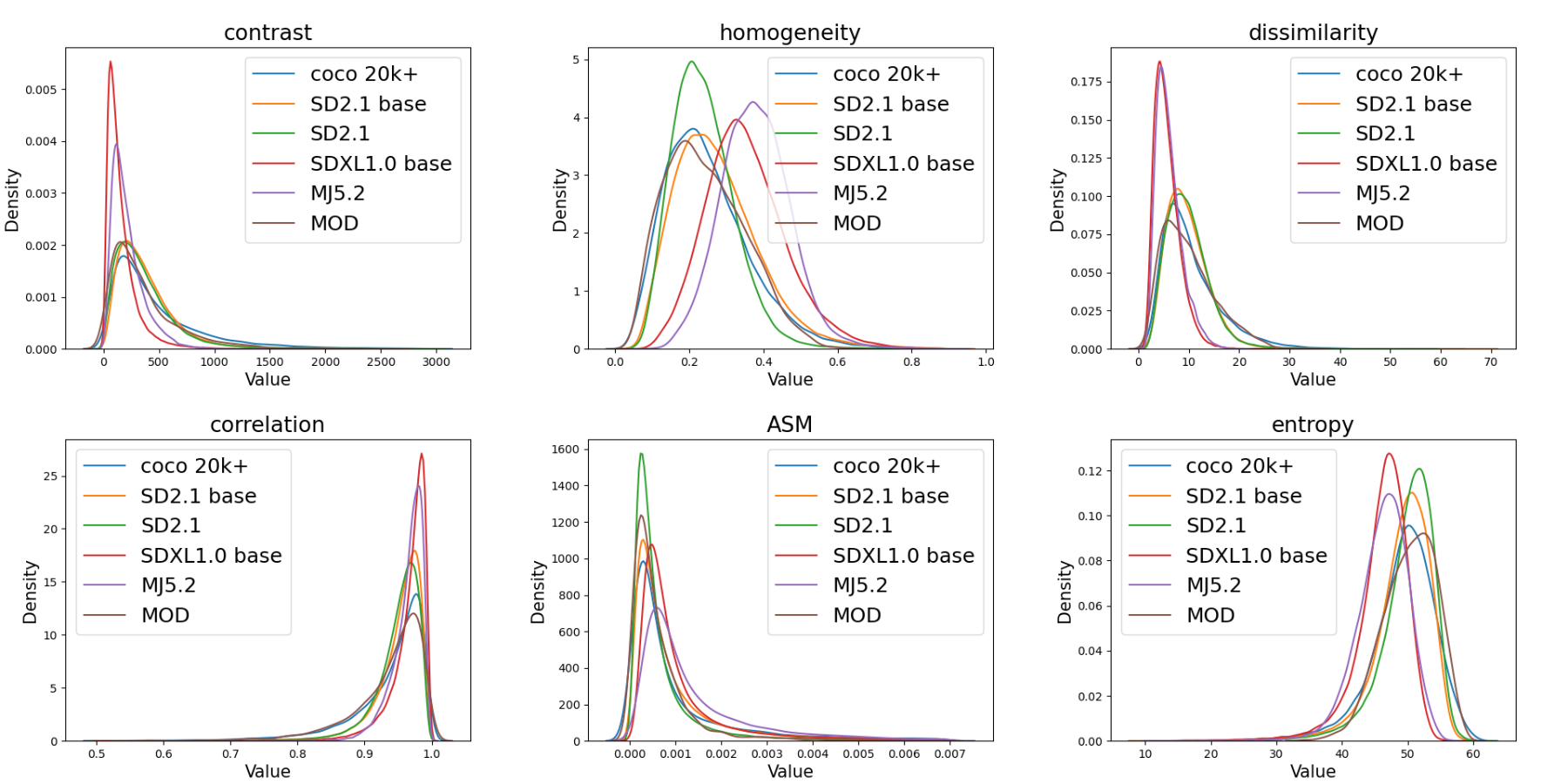
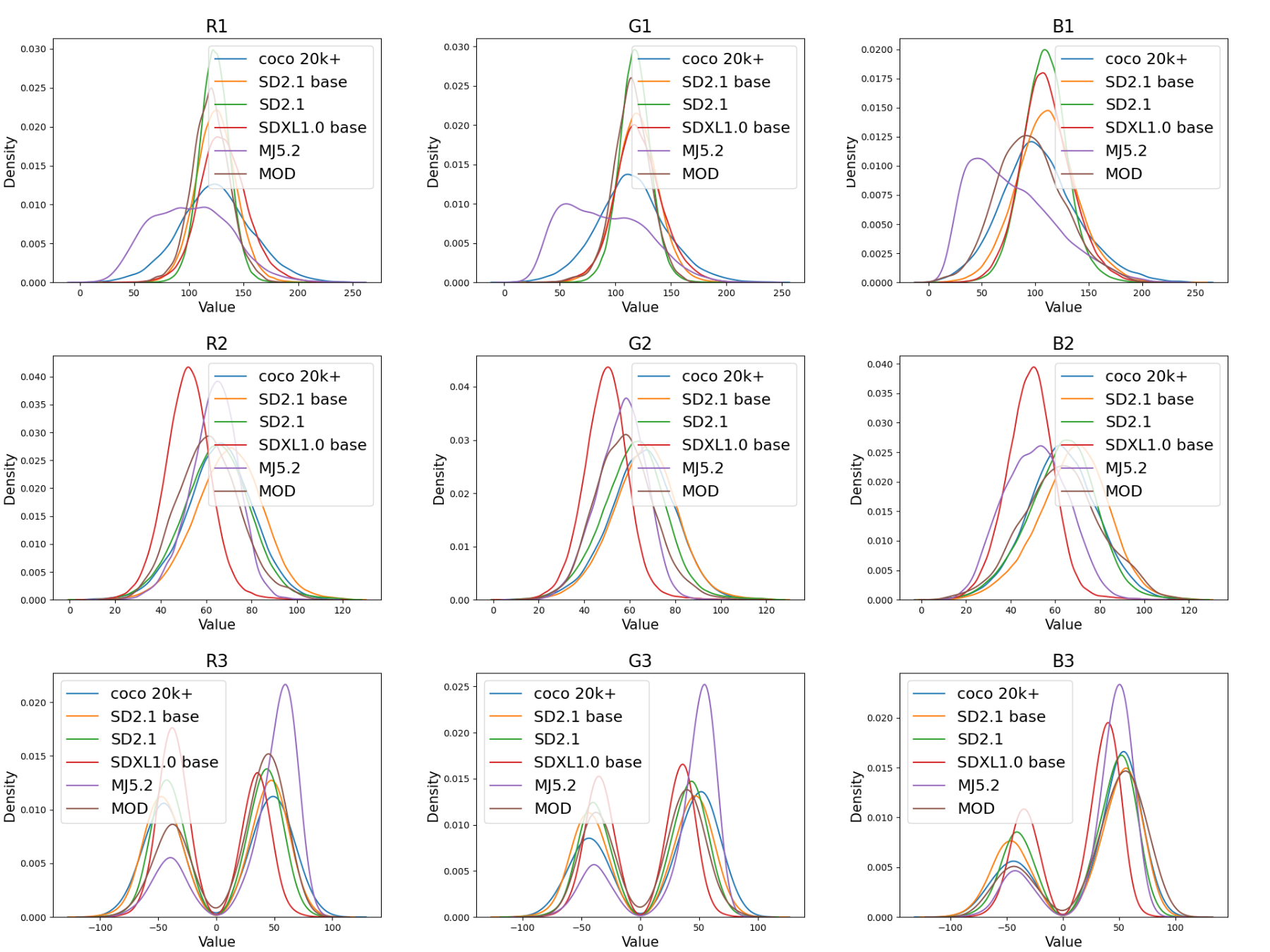
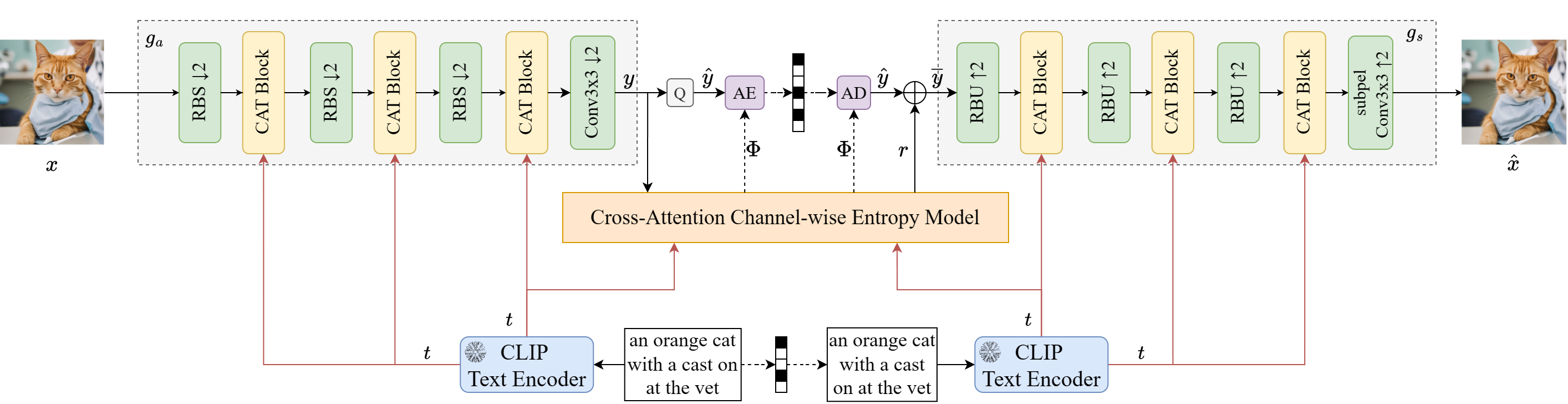
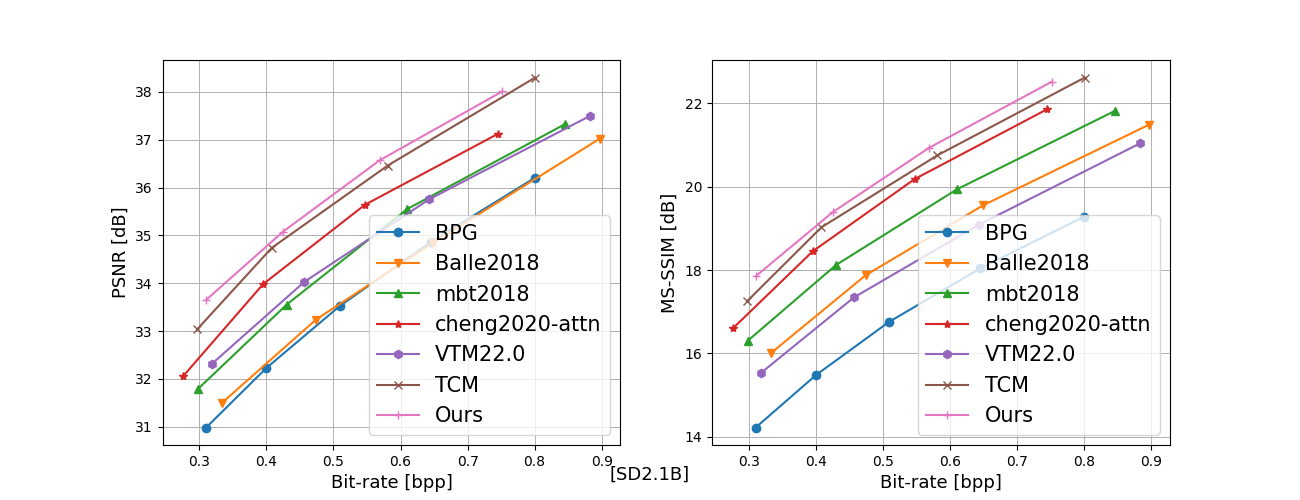
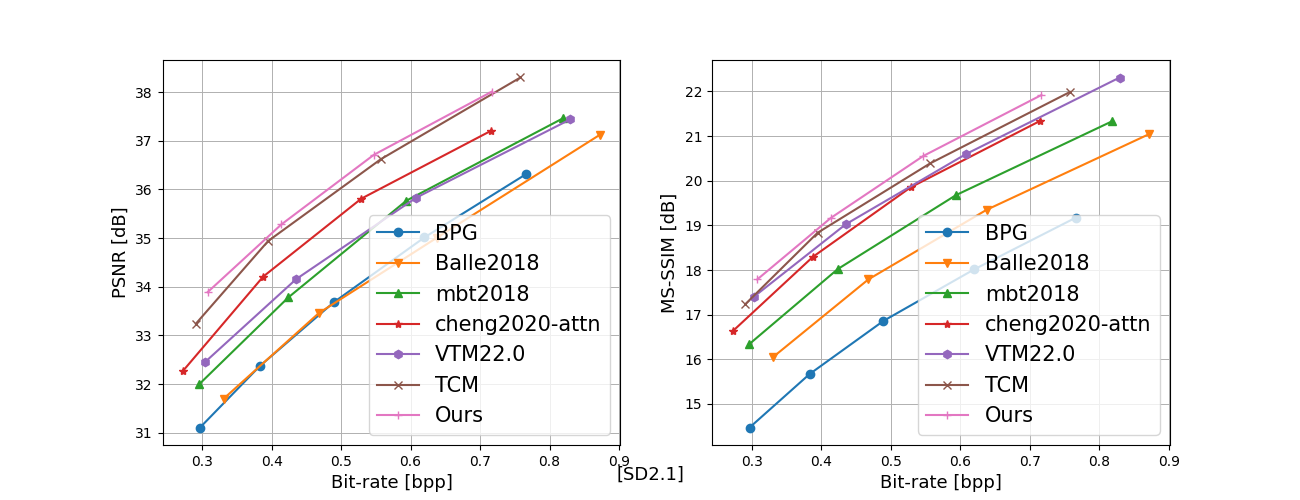
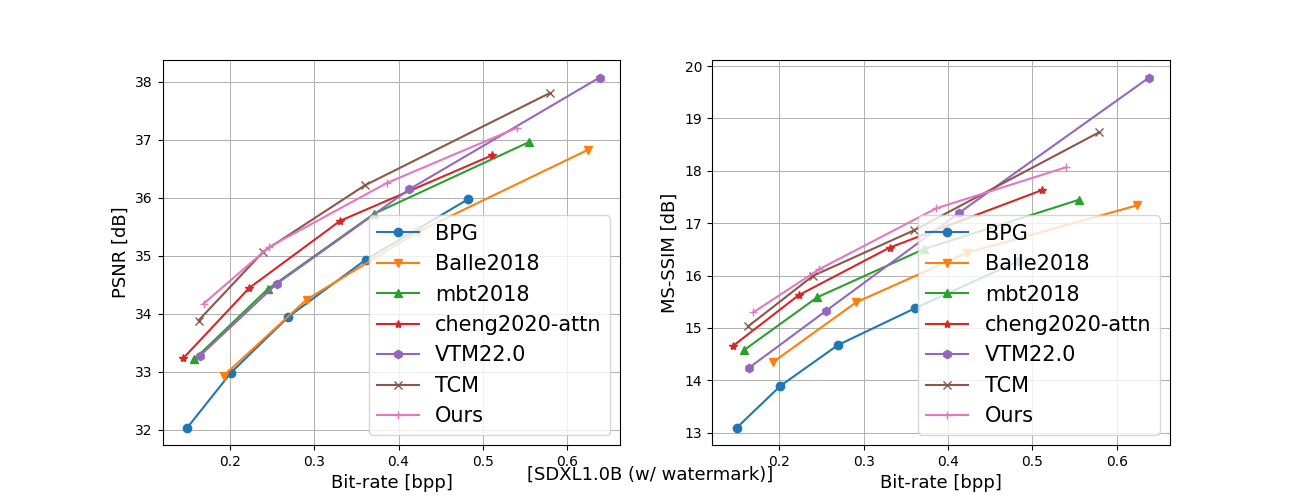
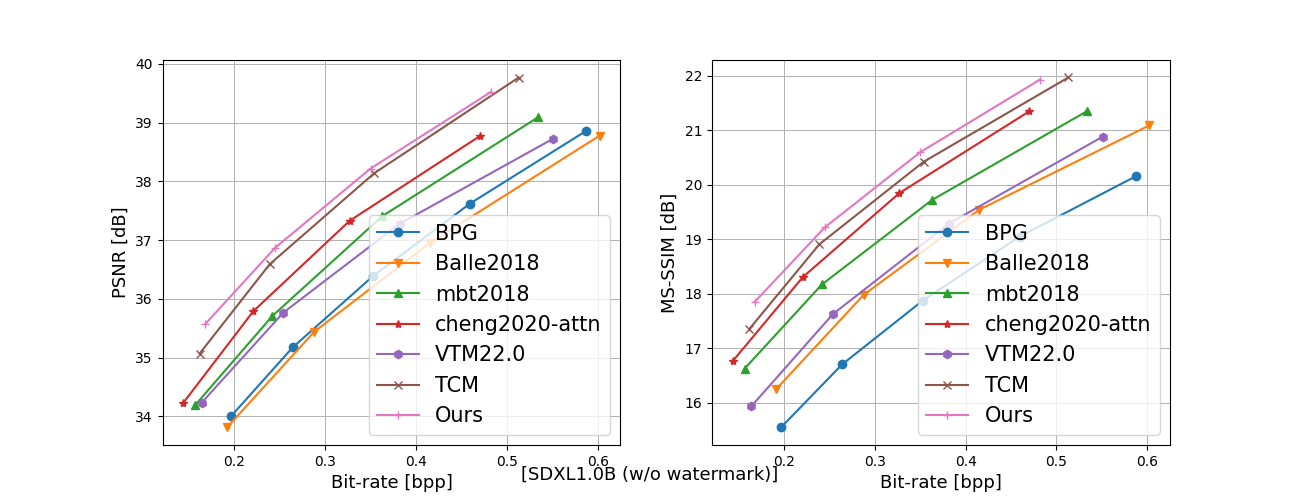
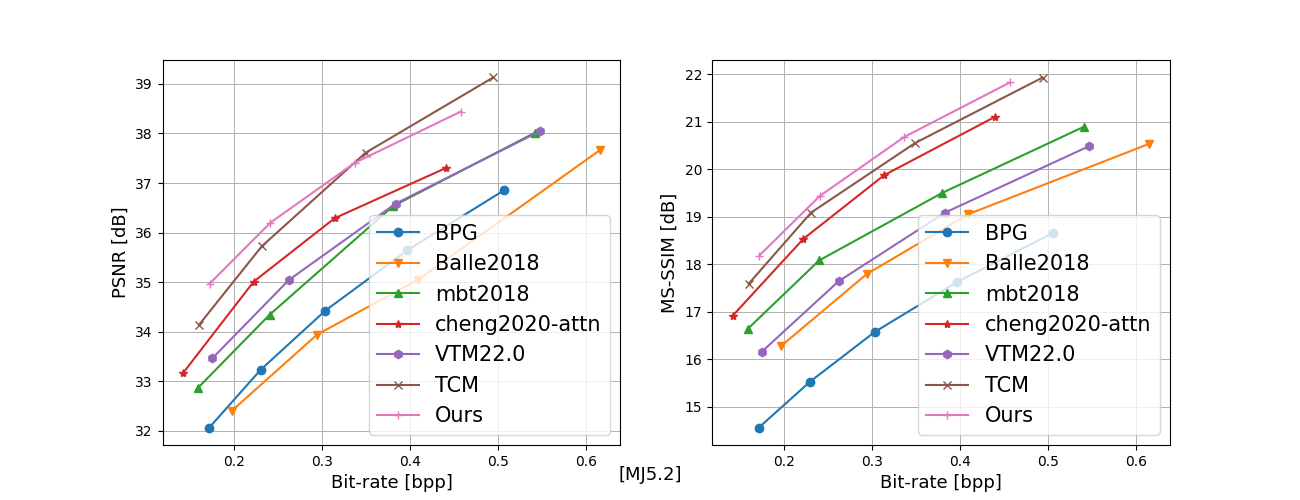
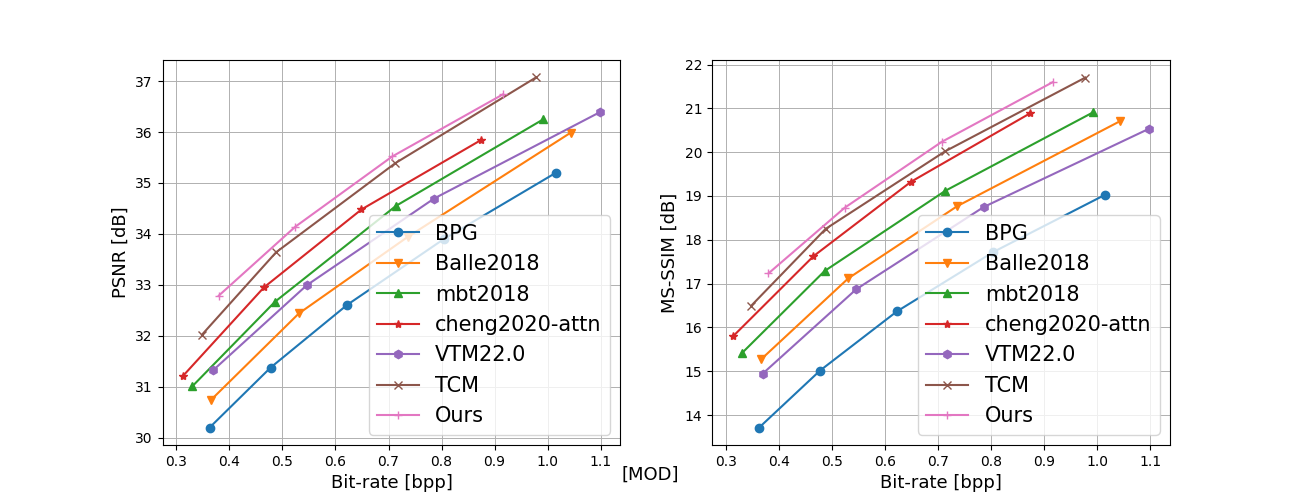
In recent years, artificial intelligence-generated content (AIGC) enabled by foundation models has received increasing attention and is undergoing remarkable development. Text prompts can be elegantly translated/converted to photo-realistic high-quality images. This notable feature, however, has introduced extreme bandwidth requirements in compression and transmission of millions of AI-generated images (AIGI) for those AIGC services. Despite this, research on compression methods for AIGI is notably absent but undeniably necessary. This research addresses this critical gap by introducing the pioneering AIGI dataset, PKU-AIGI-500K, encompassing over 528k+ images and 105k+ diverse and comprehensive prompts derived from five major foundation models. Through this dataset, we delve into the exploration and analysis of the essential characteristics of AIGC images and empirically prove that existing data-driven lossy compression methods obtain sub-optimal or less efficient rate-distortion performance without fine-tuning, primarily due to a domain shift between AIGIs and natural ones. We thoroughly benchmark the rate-distortion performance and runtime complexity analysis of conventional and learned image coding solutions that are openly available, revealing new insights for emerging studies in AIGI compression. Moreover, to harness the full potential of redundant information in AIGI and its corresponding text, we propose an AIGI compression model (Cross-Attention Transformer Codec, CATC) trained on this dataset as a strong baseline. Subsequent experimental results demonstrate that our proposed model is able to achieve up to 30.09% bitrate reduction compared to the state-of-the-art (SOTA) H.266/VVC codec and outperforms the SOTA learned codec, which paves the way for future research in the field of AIGI compression.


































@inproceedings{duan2024neural,
title={Neural Compression for AI Foundation Model Generated Images: Evaluation and Benchmark},
author={Duan, Xunxu and Liu, Hongbin and Zhang, Li and Jia, Chuanmin},
booktitle={2024 Data Compression Conference (DCC)},
pages={553--553},
year={2024},
organization={IEEE}
}
@article{duan2024pku,
title={PKU-AIGI-500K: A Neural Compression Benchmark And Model for AI-Generated Images},
author={Duan, Xunxu and Ma, Siwei and Liu, Hongbin and Jia, Chuanmin},
journal={IEEE Journal on Emerging and Selected Topics in Circuits and Systems},
year={2024},
publisher={IEEE}
}